Azkaban在LinkedIn实施,以解决Hadoop作业依赖性问题。我们有需要按顺序运行的工作,从ETL工作到数据分析产品。
最初是单一服务器解决方案,随着多年来Hadoop用户数量的增加,Azkaban已经发展成为一个更强大的解决方案。
Azkaban由3个关键组成部分组成:
关系数据库(MySQL)
AzkabanWebServer
AzkabanExecutorServer
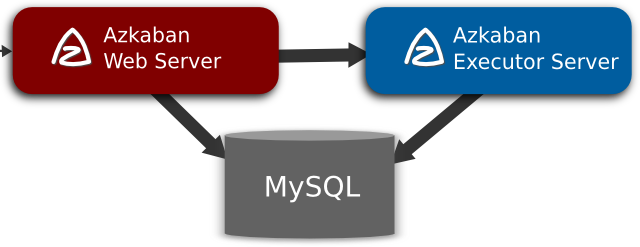
关系数据库(MySQL)
Azkaban使用MySQL来存储其大部分状态。AzkabanWebServer和AzkabanExecutorServer都访问数据库。
AzkabanWebServer服务器使用db的原因如下:
项目管理 - 项目,项目权限以及上载的文件。
执行流状态 - 跟踪执行流程以及Executor正在运行它们。
以前的流程/作业 - 搜索以前执行的作业和流程以及访问其日志文件。
调度程序 - 保持计划作业的状态。
SLA - 保留所有sla规则
AzkabanExecutorServer使用db的原因如下:
访问项目 - 从数据库中检索项目文件。
执行流/作业 - 检索和更新正在执行的流的数据
日志 - 将作业和流的输出日志存储到数据库中。
交互依赖性 - 如果流在另一个执行程序上运行,它将从数据库中获取状态。
AzkabanWebServer
AzkabanWebServer是所有Azkaban的主要经理。它处理项目管理,身份验证,调度程序和执行监视。它还可用作Web用户界面。
使用Azkaban很容易。Azkaban使用*.job键值属性文件来定义工作流中的各个任务,使用_dependencies_属性来定义作业的依赖关系链。这些作业文件和相关代码可以*.zip通过Azkaban UI或通过curl 存档到Web服务器中并上传。
AzkabanExecutorServer
以前版本的Azkaban在单个服务器中同时具有AzkabanWebServer和AzkabanExecutorServer功能。Executor后来被分成了自己的服务器。拆分这些服务有几个原因:如果一个服务器出现故障,我们很快就能够扩展执行的数量并回退到运行的执行程序。此外,我们能够以最小的用户影响推出Azkaban的升级