应用场景:从存储池获取RW Volume,挂载到指定Node上,并在该Node上启动持久化应用MySQL。
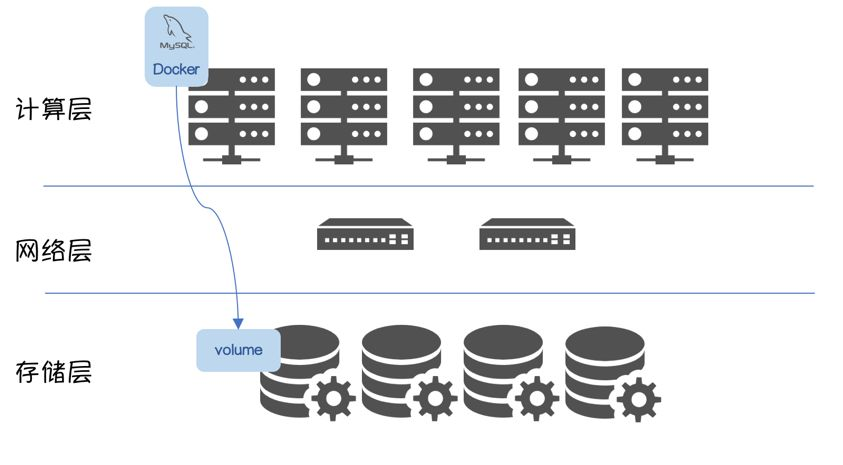
Volume的使用流程是
生成Volume
mount到数据库实例所在节点,数据库启动

复杂场景
从存储池获取Volume,挂载到指定Node上,并在该Node上启动持久化应用MySQL
MySQL具备重建/故障切换/重新调度能力
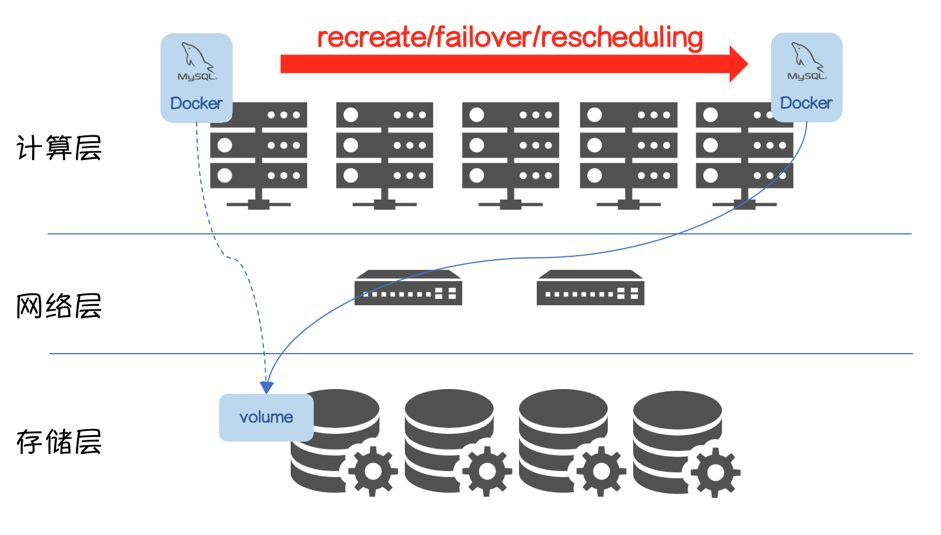
Volume的使用流程将变得复杂一些:
生成Volume
mount到数据库实例所在节点,数据库启动
数据库实例因为recreate/failover/rescheduling,被调度新节点
Volume从源节点unmount

复杂场景-02
多数情况下,kubernetes不会直接管理bare-metal,而是运行在第三方的Cloud Provider(GCE/Azure/OpenStack)。Kubernetes作为Volume的使用者,由Cloud Provider负责Volume的生命周期。
因此,mount/unmount会发生一些变化:
Volume在mount之前,需要通知Cloud Provider
Volume在unmount之后,需要通知Cloud Provider
如果Volume在unmount之后,没有通知Cloud Provider,Cloud Provider将保证Volume不会挂载到其他Node。
而“多点挂载”在大多数场景下会导致Data Corruption,因此上面的两个步骤十分必要。
Cloud Provider需要感知Volume的使用场景,比如,GCE是不允许RW Volume同时挂载到多个节点,而这两个步骤称为attach/detach
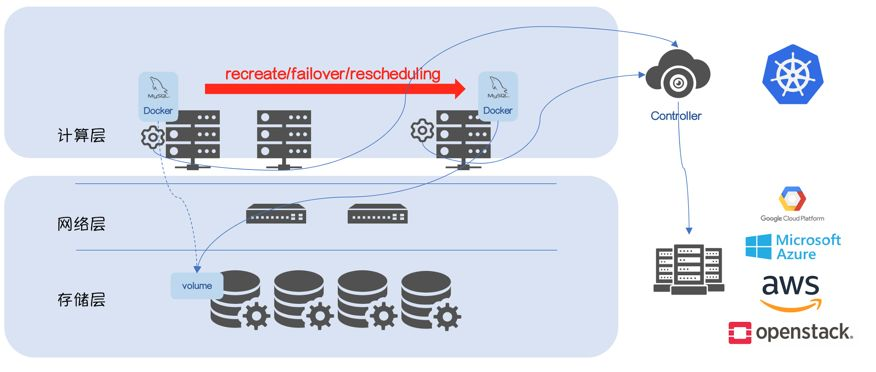
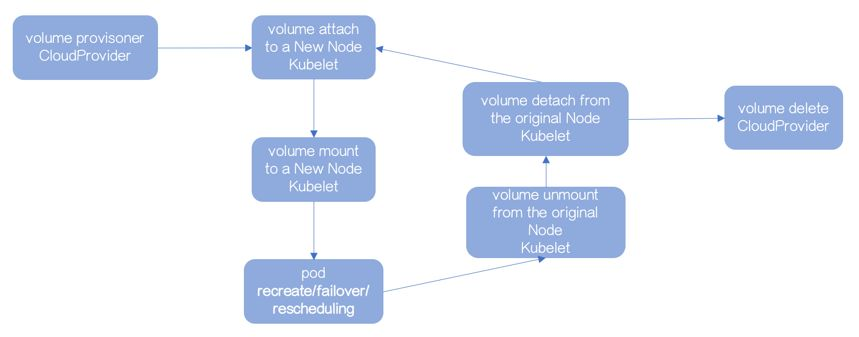
Volume的使用流程:
生成Volume
attach到数据库实例所在节点
mount到数据库实例所在节点,数据库启动
数据库实例因为recreate/failover/rescheduling,被调度到其他节点
Volume从原节点unmount
Volume从原节点detach
attach到新节点
mount到新节点,数据库启动
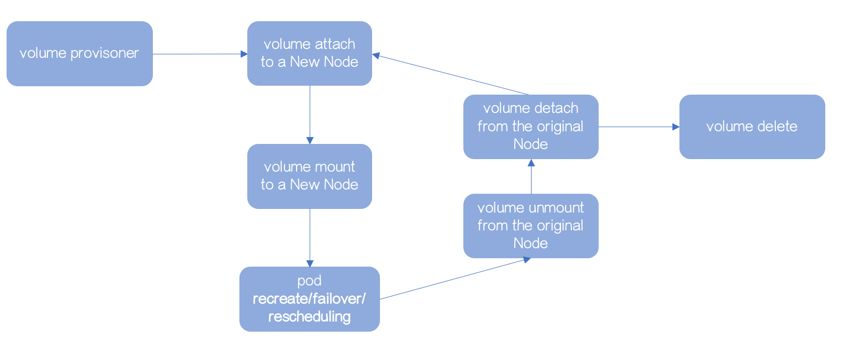
复杂场景-03
在kubernetes 1.3之前,通知Cloud Provider的工作由kubelet完成,会由Volume Plugin适配第三方Cloud Provider的逻辑。
kubelet是运行在Node端的Agent。
一旦Node重启/Crash/网络故障,都会导致无法通知Cloud Provider。此时,即使Volume已经没有应用访问,但Cloud Provider也不会让任何节点使用它。
复杂场景-04
kubernetes 1.3之后,尝试使用专门的Controller管理Attach和Detach操作。

该Controller称为AttachDetach Controller,运行在已有的Controller Plane上。

通常,使用volumes.kubernetes.io/controller-managed-attach-detach 启动该特性。
问题继续-01
attach-mount-unmount-detach流程的串行有序是保证数据不被写坏的基础。
Volume在mount之前,kubelet会确认是否已经attach
Volume在detach之前,AttachDetach Controller会确认是否已经unmount
如果,Volume不能被kubelet成功的unmount,AttachDetach Controller不能进行detach操作。
AttachDetach Controller不可能无限制的等待前置动作unmount,所以通过参数maxWaitForUnmountDuration 解决问题。
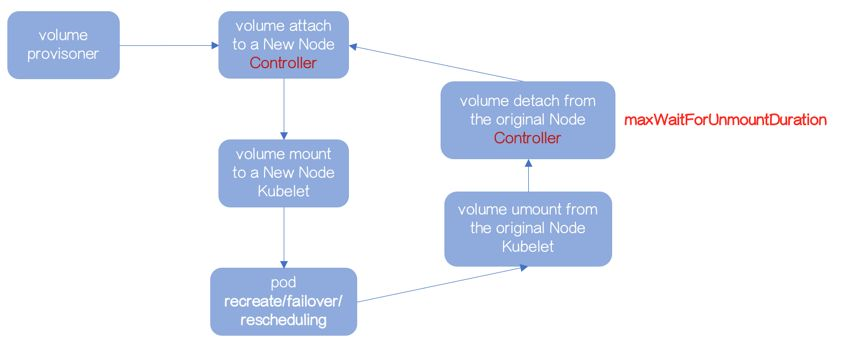
当超过maxWaitForUnmountDuration时间时,AttachDetach Controller会启动force detaching。
这样,就会破坏attach-mount-unmount-detach的串行流程,一个RW Volume在多个节点的挂载的可能性就出现了。
问题继续-02
Kubernetes集群的正常运行,依赖API Server与kubelet的正常交互,可以将其理解为“心跳”。
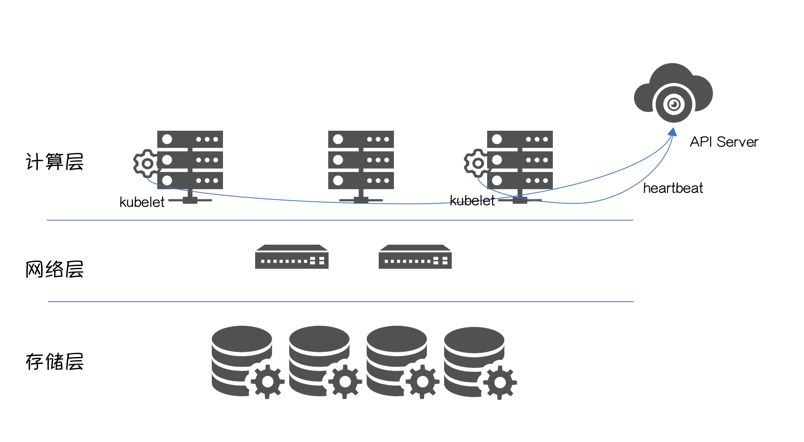
心跳丢失的可能性很多:
Node重启/Crash
Node与API Server的网络故障
Node在高负载下,kubelet无法获得CPU时间分片
一旦心跳丢失,集群将无法判断Node真实状态。运行在Controller Plane的NodeLifecycle Controller会将该节点标记为ConditionUnknown
一旦超过阈值podEvictionTimeout,NodeLifecycle Controller会对该节点上运行的MySQL进行驱逐,Scheduler会将MySQL调度到其他的available节点。
配合force detaching导致的“多点挂载”,多个实例对同一个Volume的Write将会导致Data Corruption。

【参考】
1。 原文链接:https://docs.google.com/document/d/1Q0xYOGpHvZ0LFXpzG98f6tZeWguBjgvBaGrSDiTkMXM/edit