混淆矩阵(Confusion Matrix)是大多数评价指标的基础,也是理解AUC的基础。
假如,样本数据分类结束后的混淆矩阵
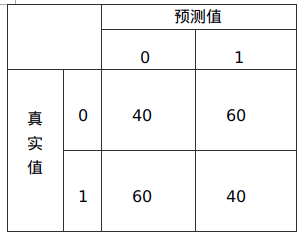
布尔相关的混淆矩阵
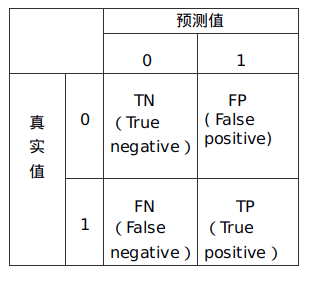
混淆矩阵包括:
TN:True Negative,真阴率,表明实际是负样本,预测也是负样本的数量
FP:False Positive,假阳率,表明实际是负样本,预测却是正样本的数量
FN:False Negative,假阴率,表明实际是正样本,预测却是负样本的数量
TP:True Positive,真阳率,表明实际是正样本,预测也是正样本的数量
常见的准确率,精确率,召回率,F1-Score,AUC都是建立在混淆矩阵基础上。
Accuracy:准确率,正确的占总的数目的比例,(TN+TP)/All=(40+40)/100=0.8
Precision:精准率,正确的正类占判断数目的比例,表示为正的数据有多少是正确的,TP/(TP+FP)=40/(40+60)=0.4
Recall:召回率,判断正确的正类占应该判断正确的正类的比例,TP/(TP+FN)=40/(40+60)=0.4
F1-Measure:精确值和召回率的调和均值,2*R*R/(P+R)=2*0.4*0.4/(0.4+0.4)=0.4
AUC&ROC
AUC是模型评价指数,只能用于二分类模型评价。相比于Accuracy和Precision,AUC与Logloss(损失函数)要更好。
AUC(Area Under Curve),是ROC曲线(Receiver Operating Characteristic Curve,接收者操作特征曲线)下边的面积。
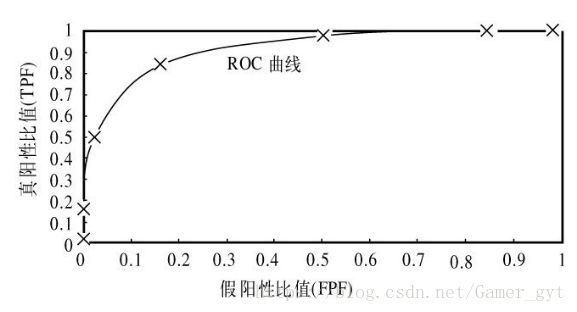
其中,X轴是假阳率FP/(TN+FP),Y轴是真阳率TP/(FN+TP)
ROC曲线不仅用于比较分类器,而且可以基于成本效益分析做出决策。最佳的分类器应该尽可能位于左上角,这意味着,分类器在假阳率很高的同时,真阳率很高。
【参考】
1。Thinkgamer:https://blog.csdn.net/Gamer\_gyt/article/details/79945987