Spark MLlib的Pipelines概念与scikit-learn 比较类似。
| 概念 | 说明 |
|---|---|
| DataFrame | ML数据集,可以处理不多样类型,包括文本、特征向量、标签值和预测值 |
| Transformer | 算法,将DataFrame转变为其他的DataFrame |
| Estimator | 算法,适用于DataFrame产生Transformer |
| Pipeline | 将多个Transformer和Estimators连接起来 |
| Parameter | Transformer和Estmators共享设置参数的API |
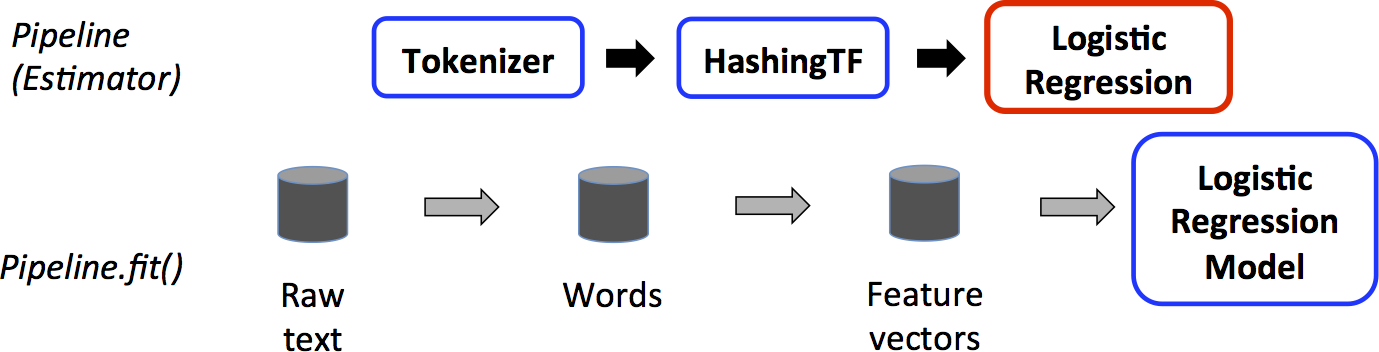
训练阶段的pipeline
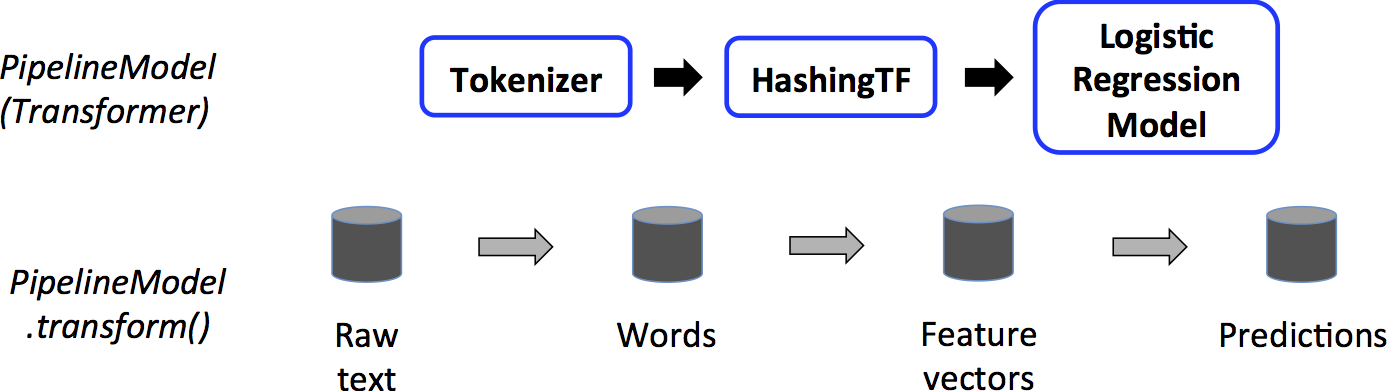
预测阶段的pipeline
程序示例
引入依赖
from pyspark.ml.linalg import Vectors
from pyspark.ml.classification import LogisticRegression
准备训练数据,创建DataFrame
training = spark.createDataFrame([
(1.0, Vectors.dense([0.0, 1.1, 0.1])),
(0.0, Vectors.dense([2.0, 1.0, -1.0])),
(0.0, Vectors.dense([2.0, 1.3, 1.0])),
(1.0, Vectors.dense([0.0, 1.2, -0.5]))], ["label", "features"])
创建逻辑回归实例,并打印参数
lr = LogisticRegression(maxIter=10, regParam=0.01)
print("LogisticRegression parameters:\n" + lr.explainParams() + "\n")
训练数据,生成模型,并查看训练的参数
model1 = lr.fit(training)
print("Model 1 was fit using parameters: ")
print(model1.extractParamMap())
指定Estimator的参数
paramMap = {lr.maxIter: 20}
paramMap[lr.maxIter] = 30
paramMap.update({lr.regParam: 0.1, lr.threshold: 0.55})
合并paramMaps
model2 = lr.fit(training, paramMapCombined)
print("Model 2 was fit using parameters: ")
print(model2.extractParamMap())
准备测试数据
test = spark.createDataFrame([
(1.0, Vectors.dense([-1.0, 1.5, 1.3])),
(0.0, Vectors.dense([3.0, 2.0, -0.1])),
(1.0, Vectors.dense([0.0, 2.2, -1.5]))], ["label", "features"])
生成并查看预测值
prediction = model2.transform(test)
result = prediction.select("features", "label", "myProbability", "prediction") \
.collect()
for row in result:
print("features=%s, label=%s -> prob=%s, prediction=%s"
% (row.features, row.label, row.myProbability, row.prediction))