Tensorflow 是一个实现机器学习算法的接口,同时也是执行机器学习算法的框架。它前端支持Python、C++、Go、Java等,后端使用C++、CUDA等。
Tensorflow实现的算法可以在众多异构系统上使用,如Android、iPhone、普通的CPU、大规模GPU集群等。
除了执行深度学习算法,Tensorflow还可以用来实现很多其他算法,包括线性回归、逻辑回归、随机森林等。
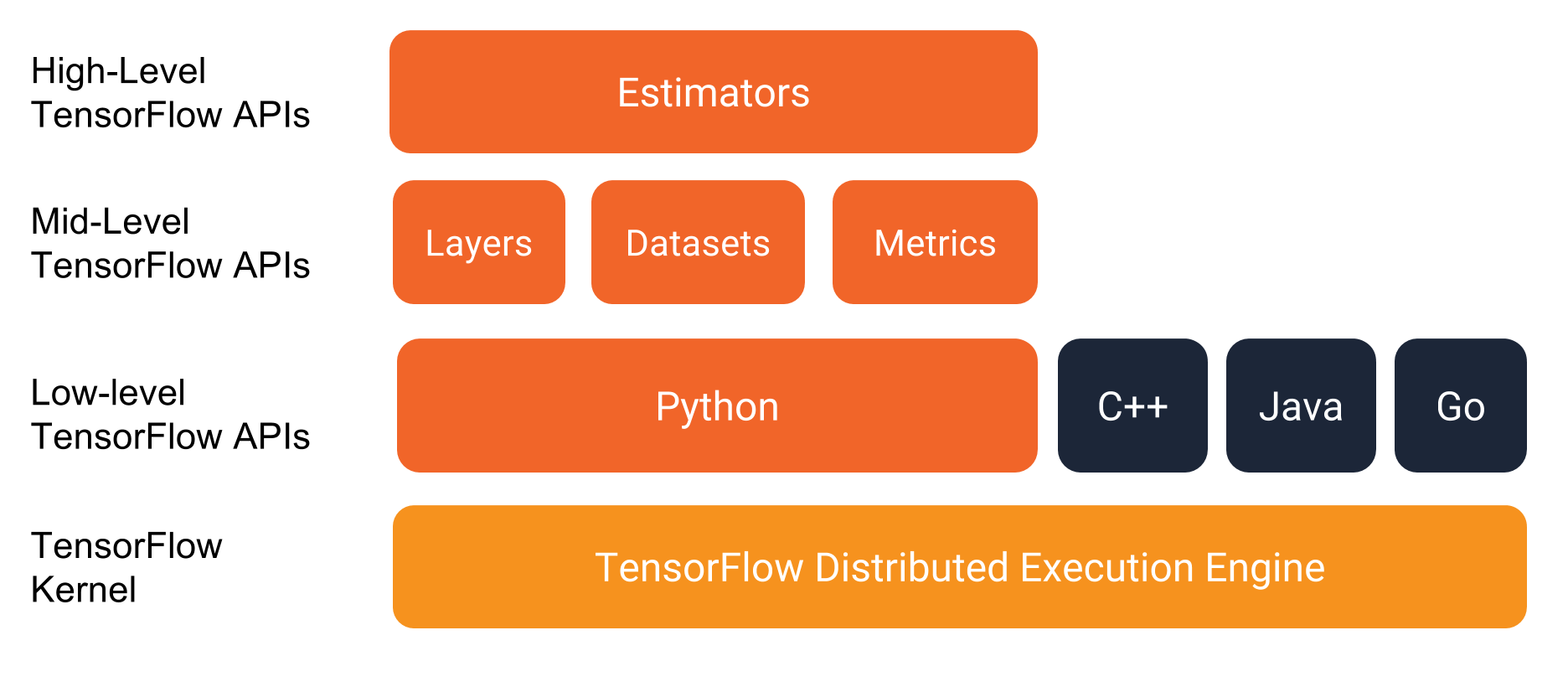
编程模型
Tensorflow种的计算可以表示为一个有向图,或称为计算图,其中每一个运算操作作为一个节点,节点与节点之间连接称为边。
在计算图的边中流动(flow)的数据称为张量(tensor)。
用户可以使用Python、C++、Go、Java等语言设计这个数据计算的有向图。
Session
Session是用户使用Tensorflow时的交互接口,用户可以通过Session的Extend方法添加新的节点和边,用以创建计算图;可以通过Session的Run方法执行计算图。
对绝大多数用户来说,他们只会创建一次计算图,然后反复执行整个计算图或是其中的一部分子图。
在大多数运算中,计算图被反复执行,而数据(tensor)不会被持续保留。
Variable是特殊的运算操作,可以将一些需要保留的tensor储存在内存或现存,比如神经网络模型参数。
每一次执行计算图,Variable中的tensor会被保存,同时计算过程中的tensor会被更新。
实现原理
tensorflow的client通过Session接口与Master及多个Worker相连。
每个Worker可以与多个硬件(device)相连,并负责管理device。
master负责指导所有Worker按流程执行计算图。
Tensorflow有单机模式和分布式模式两种实现。
单机模式是指client、master、worker全部在一台机器的同一个进程。
分布式模式是指client、master、worker在不同机器的不同进程,同时由集群调度系统统一管理各项任务。
Tensorflow中的每个worker可以管理多个设备,每个设备的name包含硬件类别、编号、任务号(单机版没有)
# 单机模式
/job:localhost/device:cpu:0
# 分布式模式
/job:worker/task:17/device:gpu:3
计算方式
当只有一个硬件设备时,计算图会根据依赖顺序执行。当一个节点的依赖数为0时,该节点将加入ready queue,同时下游所有节点的依赖数减1。这就是标准的计算拓扑序方式。
tensorflow与spark
Tensorflow和Spark的核心都是一个数据计算的流式图,Spark面向的是大规模的数据,支持SQL等操作,而Tensorflow主要面向内存足以装载模型参数的环境。